When developing with python people usually want to store some data. If this data is quite big and/or contains personal information it is not advised to store it in github (or other git providers). One good option is to store it in dropbox.
Dropbox has a really nice package that you can install with
pip install dropbox
It is not really difficult to use it but I noticed that every time I wanted to I had to look for old code. So I decided that I could create a post that explained everything.
The first thing to do is create an app inside dropbox since you cannot get a token without it. To do so go to dropbox developers.
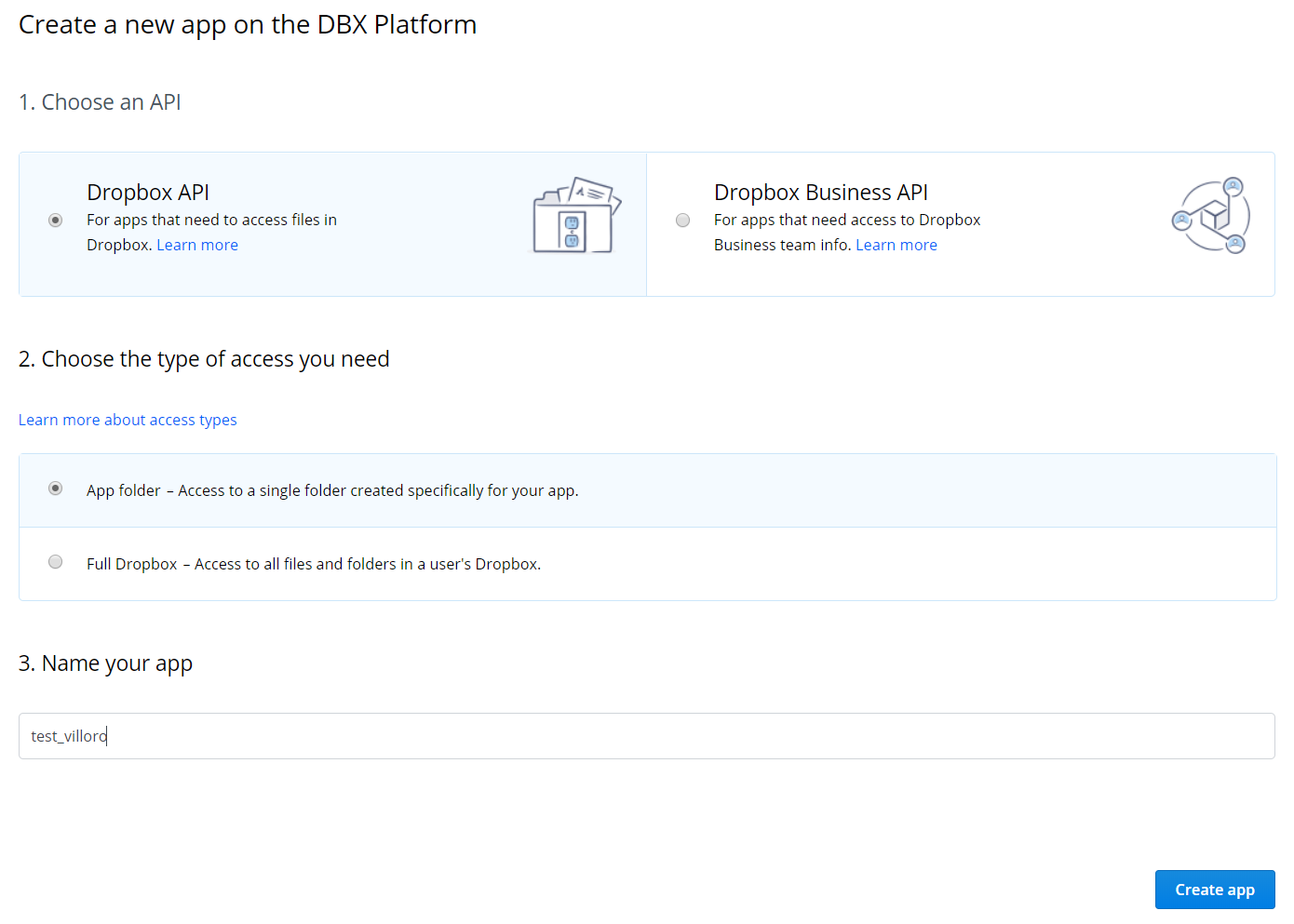
Register a new app that will use Dropbox API and will acces only the app folder. Once you have create the app go to the app settings page and create a token.
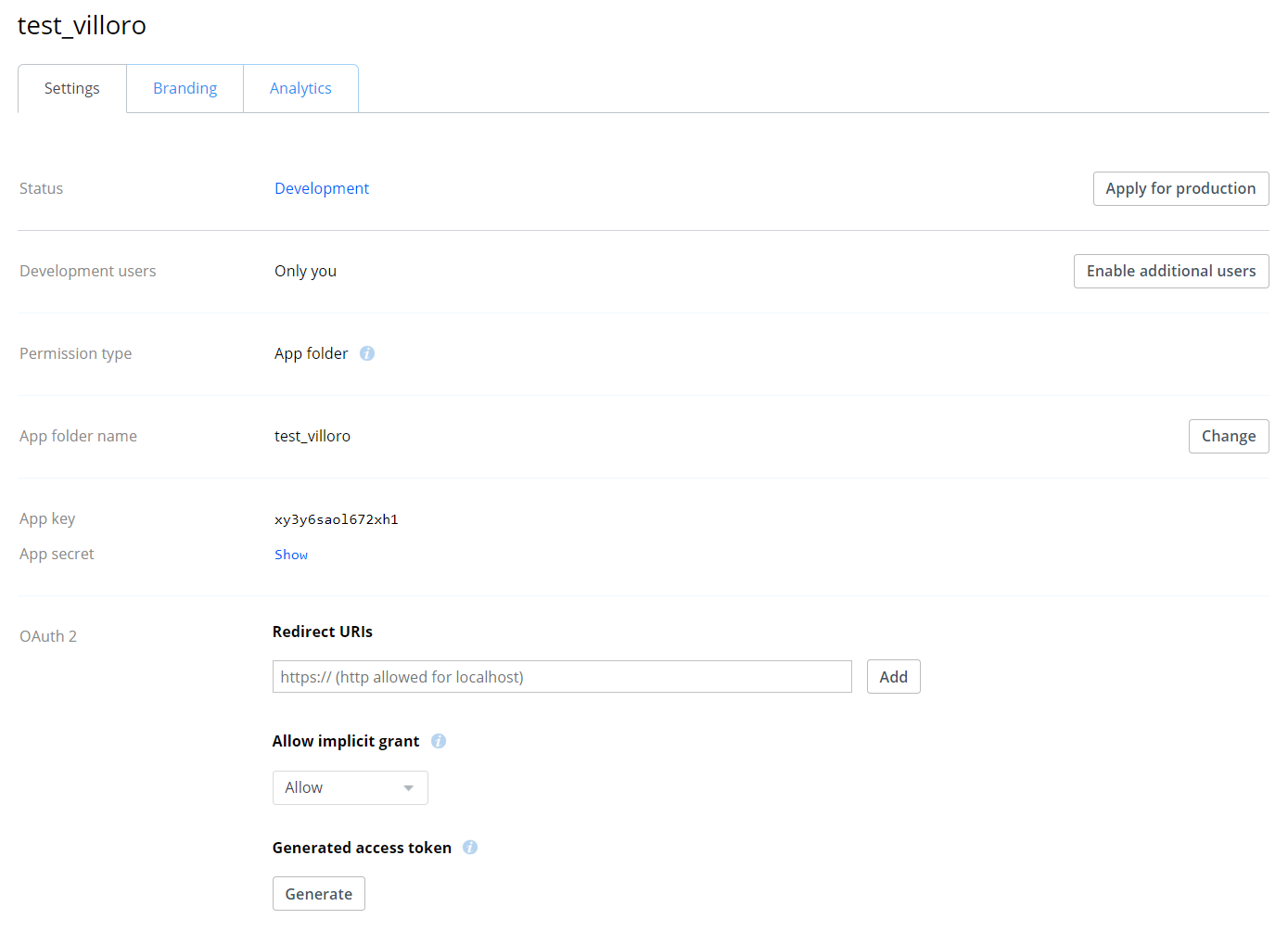
You can now store that secret in a safe way (for example as an environment variable or a hidden file).
The key to write or read files is using io.BytesIO object.
As an example you can create this object with:
txt = "Hello World" stream = io.BytesIO(txt.encode()) stream.seek(0) # Here you do whatever you need stream.close()
Or even better you can use the with statement so that you don't need to close the stream:
txt = "Hello World" with io.BytesIO(txt.encode()) as stream: stream.seek(0) # Here you do whatever you need
It is important to run
stream.seek(0)to go to the begining of the stream.
The first thing you need to do is to init the dropbox object with:
import io import dropbox DBX = dropbox.Dropbox(token)
After creating the DBX instance you can upload files using DBX.files_upload.
You will need to create the io.BytesIO object and upload it.
txt = "Hello World" with io.BytesIO(txt.encode()) as stream: stream.seek(0) # Write a text file DBX.files_upload(stream.read(), "/test.txt", mode=dropbox.files.WriteMode.overwrite)
To allow overwriting you need to pass mode=dropbox.files.WriteMode.overwrite to the function DBX.files_upload.
Important: filenames should start with
/. It won't work without it.
To write a dictionary-like file you can use the following:
import json data = {"a": 1, "b": "hey"} with io.StringIO() as stream: json.dump(data, stream, indent=4) # Ident param is optional stream.seek(0) DBX.files_upload(stream.read().encode(), "/test.json", mode=dropbox.files.WriteMode.overwrite)
It is very similar to writting a json:
import yaml data = {"a": 1, "b": "hey"} with io.StringIO() as stream: yaml.dump(data, stream, default_flow_style=False) stream.seek(0) DBX.files_upload(stream.read().encode(), "/test.yaml", mode=dropbox.files.WriteMode.overwrite)
This time we are encoding the stream to transform it to bytes.
import pandas as pd df = pd.DataFrame([range(5), list("ABCDE")]) with io.BytesIO() as stream: with pd.ExcelWriter(stream) as writer: df.to_excel(writer) writer.save() stream.seek(0) DBX.files_upload(stream.getvalue(), "/test.xlsx", mode=dropbox.files.WriteMode.overwrite)
The key is to use the ExcelWriter from pandas.
Unfortunatelly it is not possible to dump a csv directly with Pandas into a StringIO at this time (More info: here)
However there is a workaround:
df = pd.DataFrame([range(5), list("ABCDE")]) data = df.to_csv(index=False) # The index parameter is optional with io.BytesIO(data.encode()) as stream: stream.seek(0) DBX.files_upload(stream.read(), "/test.csv", mode=dropbox.files.WriteMode.overwrite)
To read a file you can use DBX.files_download.
This will return some metadata as the first parameter and the result of the API call as the second.
_, res = DBX.files_download("/test.txt") res.raise_for_status() with io.BytesIO(res.content) as stream: txt = stream.read().decode()
Remember to decode the stream to transform it from bytes to string
_, res = DBX.files_download("/test.json") with io.BytesIO(res.content) as stream: data = json.load(stream)
_, res = DBX.files_download("/test.yaml") with io.BytesIO(res.content) as stream: data = yaml.safe_load(stream)
You should always use
yaml.safe_loadinstead ofyaml.load
_, res = DBX.files_download("/test.xlsx") with io.BytesIO(res.content) as stream: df = pd.read_excel(stream, index_col=0)
If you do not want a new dummy index use
index_col=0.
_, res = DBX.files_download("/test.csv") with io.BytesIO(res.content) as stream: df = pd.read_csv(stream, index_col=0)
To delete a file simply call DBX.files_delete(filename).
With this post you should have enough to work with dropbox using python.
However, if you need to work another format look on how to create a StringIO object that represent this format.