Predict the transcription from raw audio.
The idea of this project was to create a full pipeline that would take raw sound and then predict the transcription.
The first step I did was to work with different ways to extract features from audio.
Then I tested different Neural Network (NN) architectures in order to crate a good model that could predict with the given features.
15 models trained
2.2h average training time
Model with 1,946,957 parameters
I did this project as a part of the Artificial Intelligence Nanodegree (udacity moved the project to the Natural Language Processing Nanodegree). The purpouse of this project was to learn how to process audio in order to extract features. One key aspect about sound recognition is the time.
The aim is to have a system that given raw audio is able to predict the transcription of the spoken language. The pipeline is summarized in this image:

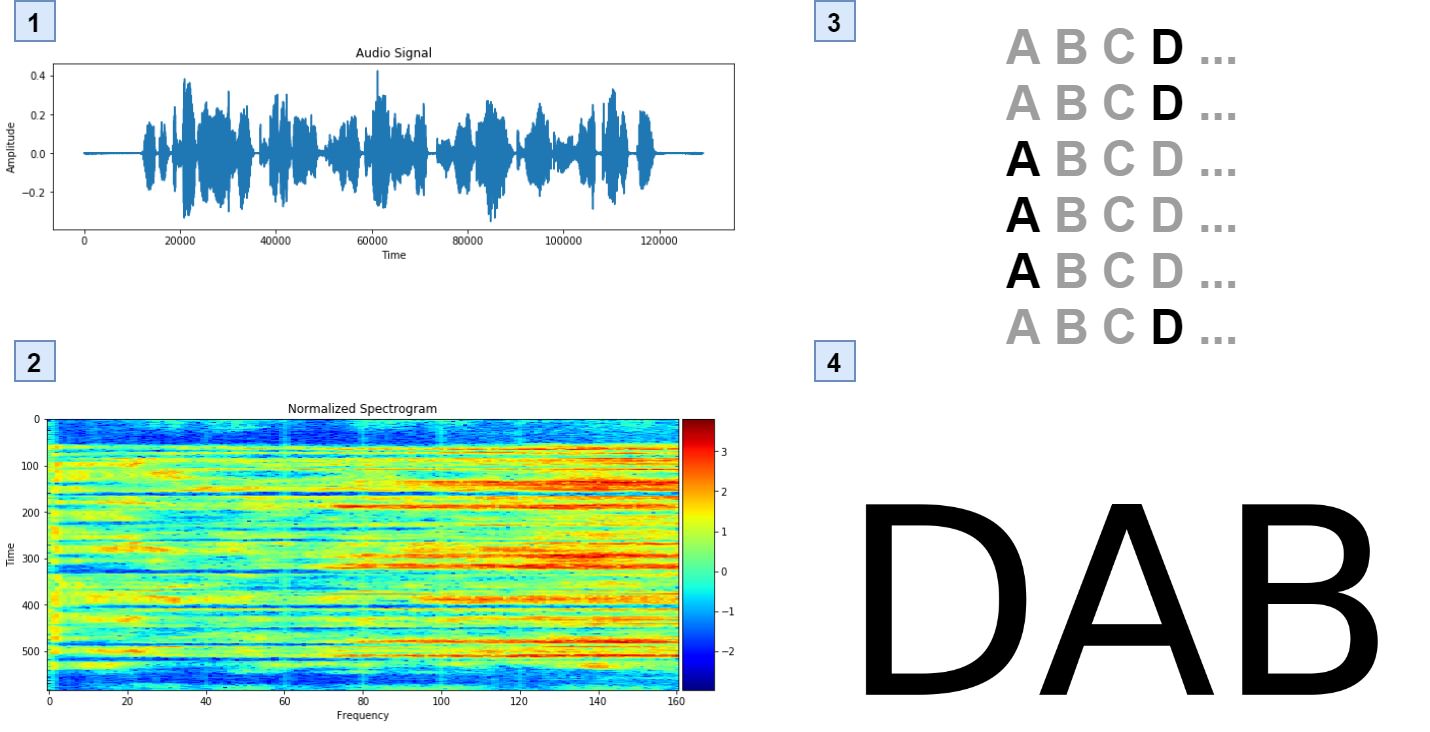
There are two ways to extract features from audio and both were tested to see which one gave the best results.
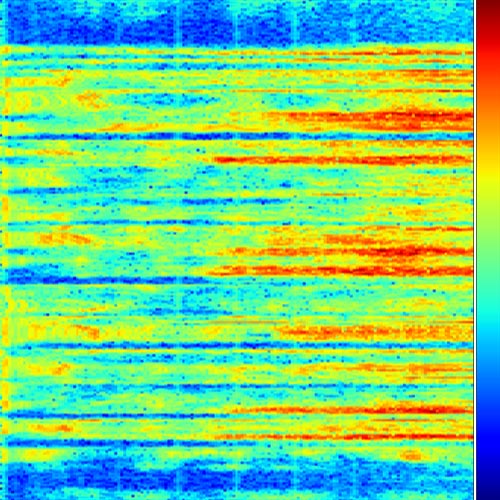
The first one is to use the raw audio and transform it to a spectogram where one dimension represents time and the other one the frequency. This is done using Fast Fourier Transform (FFT).
The secon one is to use Mel-Frequency Cepstral Coefficients (MFCC). In general this consists of using only the frequencies that humans can recognize in order to reduce the dimensionality of the data.
In this part I work with different Neural Network (NN) architectures to see which one performed better. There options ranged from pure Recurent Neural Networks (RNN) to combinations of Convolutional Neural Networks (CNN) + RNN. The models were:
And I ended up using a combination of all of the above:
CNN + 2 Bidirectional RNN + 2 TimeDistributed Dense
The full details of the NN can be seen in the next figure:

I used
dropoutandbatch normalizationto avoid overfitting andLeaky ReLUto avoid deadReLUs.
In order to get good results it is really important to note that this is a Connectionist Temporal Classification (CTC) problem and the loss function needs to be a CTC loss.
I only use the most probable letter at each time. It is possible to increase the performance of the system a lot by adding a language model.
A language model would use the probabilities of each letter and do a matching with possible words. This will allow much better results.
Below there is an example of the output and the real text.
True transcription:
mister quilter is the apostle of the middle classes and we are glad to welcome his gospel
Predicted transcription:
mis ter cilder is the aposol of the mitl clasos and were gllad to welkom his gosplel
It is not very good but is able to understand some things. With a language model the results would be way better.